Provide your details below to request scholarly review comments.
×
Verified Request System ®
Order Article Reprints
Please fill in the form below to order high-quality article reprints.
×
Scholarly Reprints Division ®
− Abstract
This study seeks to formalize the relationship between consciousness and linguistic data through a symmetry-based approach. It proceeds from the assumption that consciousness as a biological fact and linguistic structures—especially their formally describable patterns—are mirror images of one another. The structures of conscious linguistic composition are reflected in the organization of linguistic data, while formal linguistic patterns can be traced back to the inner, rhythmic, and symmetrical architecture of consciousness. To map this relationship, the study integrates the methodological toolkits of three coequal fields: computational linguistic encoding, rhythm-based phonology, and the historical investigation of linguistic melody.
The computational linguistic encoding relies on a custom-developed system that classifies syllables within words by typology and position. At the core of the model stands a center–periphery principle: vowels constitute the center of the structure, encircled by concentrically arranged consonants. This symmetry-based approach enables precise formal annotation of the internal structure of syllables and sheds light on recurring patterns in phonological organization. The classification introduces 55 syllable types grounded in five basic structures (e.g., open, closed, reduced, etc.), augmented by positional labelling that records whether a syllable is word-initial, word-medial, or word-final.
− Explore Digital Article Text
# I. INTRODUCTION
# 1.1 Scientific Background
Uncovering the relationship between language and consciousness is a complex challenge in modern linguistics and cognitive science. To understand this relationship, phonology, morphophonology, and formal linguistics offer a solid theoretical foundation. Phonology—especially metrical phonology and prosody—examines how sounds and rhythmic patterns are organized in language, while morphophonology studies phonological alternations in word forms. These domains reveal that symmetrical patterns are often observable in linguistic structures: for instance, alliteration lends the text a "translational" symmetry [1], and rhyme schemes may feature mirror-like repetitions (e.g., the "abba" enclosed rhyme). Similarly, among the basic units of versification—the metrical feet—we find both symmetric and asymmetric structures: the former exemplified by the pyrrhic or the spondee, the latter by the iamb and the trochee. [1] Formal linguistics seeks to describe these phenomena precisely through formal models (e.g., generative grammar, algebraic descriptions of language) that enable a rigorous, mathematically grounded representation of linguistic patterns. This scientific background suggests that there are systematic, formalizable correspondences between linguistic structures and the mental processes underlying them—including consciousness.
# 1.2 Applied Methodology
To achieve the stated aim, the study draws on the findings and methods of three main disciplines, which together provide a symmetry-based framework for the investigation:
- Computational encoding and symmetry-based linguistic classification: The first pillar is a computational linguistic analysis that encodes and classifies linguistic elements on the basis of syllable typology and position within the word. In practice, words and structures are transformed into formal codes that reflect the symmetric patterns inherent in them (for example, the symmetry of their syllable structure or recurring elements). This approach enables us to identify systematic groupings in the linguistic data and to explore the extent to which certain patterns (e.g., palindromic or rhythmic symmetries) are deliberately crafted or arise spontaneously in language use.
- Rhythm-based phonological analysis: The second pillar examines the rhythmic organization of language at the intersection of phonology and metrics (versification). Specifically, we analyze the Omagyar Mária-siralom as a case study, a text of poetic-historical significance whose verse rhythm, according to research, exhibits a distinctly iambic tendency. [2] Our analysis pays particular attention to the alternation and role of iambic and trochaic rhythms in this work. Comparing iambic (weak-strong stress pattern) and trochaic (strong-weak) cadences can reveal how symmetric and asymmetric rhythmic structures manifest in language, and how they may contribute to meaning-making or to consciously perceived effects in the listener. Metrical and phonological analysis not only maps the rhythm of the historical text but also permits broader conclusions about the extent to which linguistic rhythm may be the product of conscious linguistic composition.
- Linguistic melody and historical comparison: The third pillar investigates linguistic melody—that is, pitch and intonation in linguistic expression—with special attention to
the relationship between verse and melody. Within this framework, through historical examples, we examine how metrical form (meter, rhythm) relates to the melody of speech (prosodic patterns). For instance, prior musicological and literary scholarship has attempted to reconstruct the presumed melody of the Omagyar Maria-siralom, shedding light on the melodic aspects of how texts of the period were performed. In studying linguistic melody, we compare the roles of intonation and pitch across the versification of different eras and languages-by analyzing, for example, medieval hymns, folk hymns, and selected works of classical Hungarian poetry. This historical-comparative approach aims to determine the extent to which melodicity is a structural (and perhaps symmetric-describable) feature of language, and how it contributes to the recipient's conscious experience (the conveyance of emotions and affective tone).
These three methodological pillars form a close unity: computational encoding provides a quantitative basis for identifying linguistic patterns, while rhythm analysis and melody study supply a qualitative, interpretive framework that links these patterns to the concept of consciousness. Symmetry theory serves as a common denominator: whether text, sound, or structure is at issue, patterns of symmetry and repetition/variation are interpretable across all three areas. In this way, our methodology integrates formal and empirical approaches: computational modelling captures objective symmetries in language, while phonological-metrical analysis illuminates their conscious and aesthetic dimensions.
# 1.3 Practical Applicability
The research is not only of theoretical significance; its results can also be leveraged across numerous practical domains. Below, we highlight the most important avenues of application:
- Speech recognition and speech synthesis: In speech technology, it is crucial to account for the rhythmic and melodic (prosodic) characteristics of language. Adequate modelling of prosody is indispensable for producing natural-sounding synthetic speech [3], yet today's speech-recognition algorithms exploit the information contained in rhythm and pitch only to a limited extent [3]. Our research can contribute to more advanced recognition systems that identify speech more accurately by detecting symmetry-based rhythmic patterns, as well as to synthesis solutions that incorporate a text's melody and rhythm to produce a more natural, human-like sound.
- Natural language processing (NLP): Formal linguistic models—especially when they integrate aspects of conscious processes—can improve the performance of computational language-processing systems. Symmetry-based linguistic analysis can aid in a better understanding of sentence structures, word-form alternations, and stress patterns, which is useful for tuning translation algorithms, automatic summarizers, and grammatical parsers. This can bring us closer to machine models that also take into account the consciousness-driven aspects of human language use (for example, what pragmatic purpose a given emphasis or word-order change serves).
- Rhythmic text synthesis: The automatic generation of poetic language or rhythmic prose is a distinct domain in which the present research can be applied directly. Formalized knowledge of versification rules and rhythmic patterns makes it possible to develop algorithms capable of producing text in accentual (stress-based) or even quantitative styles. This has practical value for creative-writing applications, poetic-style chatbots, and even for emulating the rhythmic style of literary works. Rhythm-driven text generation can provide not only an aesthetic experience but also support language learning by making the roles of stress and rhythm in language more tangible for learners.
- Literary-historical interpretations: The research can also offer valuable insights into literary studies and philology. By reconstructing the rhythm and melody of historical texts (e.g., medieval poems and hymns), the circumstances of composition and mechanisms of effect for certain works can be reinterpreted. If we formally describe an old text's rhythmic-melodic patterning, we can better understand which conscious compositional principles may have guided the author, and what effect the work may have had on its contemporary audience. For example, the results of the rhythmic and melodic analysis of the Omagyar Mária-siralom can help us examine this work not only as a relic of language history but also as a poem intended for oral performance, bringing its message closer to today's audiences. The knowledge thus gained enriches literary-historical interpretations and can open a new dialogue between linguistic formalism and literary analysis.
In summary, the study's interdisciplinary approach—which combines computational linguistic encoding, rhythm-based phonology, and the study of linguistic melody—enables a more comprehensive understanding and formalization of the relationship between linguistic data and consciousness. The symmetry-based framework helps to place phenomena observed at different linguistic levels on a unified theoretical footing,
uncovering deeper interrelations between structure and meaning, form and function. The introduction presented here is a prelude to the analyses to be detailed later, grounding the hypothesis that the patterns of the conscious shaping of language can indeed be captured and systematized within a symmetry-theoretic model—one that both enriches our theoretical knowledge and leads to practical applications.
An integrated view of the disciplines of machine code, rhythm-based phonology, and linguistic melody is indispensable for terminals to communicate accurately and quickly:
# II. MACHINE ENCODING
# 2.1 The Model
Consciousness (search) $= [1:2]:[3:4]$
$1=$ Syllable template
2= Word-initial/medial/final syllables
$3=$ Word-relative syllable positions
$4=$ Word classes by syllable count
# 2.2 The Description
We classify words into word types based on their number of syllables:
D word, A word, B1 word, B2 word, B3 word, B4 word, B5 word, B6 word, B7 word, B8 word (e.g. D word = 'sztrajk'; A word = 'labda'; B1 word = 'ballada'; B2 word = 'levendula' etc.)
From these word types, we derive a classification of syllables into 55 syllable types:
D syllable;
A1 syllable, A2 syllable, A3 syllable, A4 syllable, A5 syllable, A6 syllable,
A7 syllable, A8 syllable, A9 syllable;
B1 syllable, B(2-1) syllable, B(2-2) syllable, B(3-1) syllable, B(3-2) syllable,
B(3-3) syllable, B(4-1) syllable, B(4-2) syllable, B(4-3) syllable, B(4-4) syllable,
B(5-1) syllable, B(5-2) syllable, B(5-3) syllable, B(5-4) syllable, B(5-5) syllable,
B(6-1) syllable, B(6-2) syllable, B(6-3) syllable, B(6-4) syllable, B(6-5) syllable,
B(6-6) syllable, B(7-1) syllable, B(7-2) syllable, B(7-3) syllable, B(7-4) syllable,
B(7-5) syllable, B(7-6) syllable, B(7-7) syllable, B(8-1) syllable, B(8-2) syllable,
B(8-3) syllable, B(8-4) syllable, B(8-5) syllable, B(8-6) syllable, B(8-7) syllable,
B(8-8) syllable;
C1 syllable, C2 syllable, C3 syllable, C4 syllable, C5 syllable, C6 syllable,
C7 syllable, C8 syllable, C9 syllable.
(E.g. D syllable = 'sztrájk';
A1 syllable = 'lab-'; A2 syllable = 'bal-'; A3 syllable = 'le-' etc.
B1 syllable = 'la-'; B(2-1) syllable = 'ven-'; B(2-2) syllable = 'du-' etc.
C1 syllable = 'da-'; C2 syllable = 'da-'; C3 syllable = 'la-' etc.)
We further classify syllables into five syllable classes (V = vowel, C = consonant):
1. reduced syllable (V);
2. "inorganic" (consonant-only) syllable (C; CC; CCC; CCCC);
3. open syllable (CV; CCV; CCCV);
4. closed syllable (VC; VCC; VCCC);
5. full syllable (CVC; CVCC; CVCCC; CCVC; CCVCC; CCVCCC; CCCVC; CCCVCC)
Cf. examples: $\mathrm{V} = {}^{\prime}\mathrm{a} - {}^{\prime}$ ; $\mathrm{C} = {}^{\prime}\mathrm{s} - {}^{\prime}$ ; $\mathrm{CC} = {}^{\prime}\mathrm{hm} - {}^{\prime}$ ; $\mathrm{CCC} = {}^{\prime}\mathrm{pszt} - {}^{\prime}$ ; $\mathrm{CCCC} = {}^{\prime}\mathrm{sscc} - {}^{\prime}$
$\mathrm{CV} = \mathrm{ka} - \mathrm{;CCV} = \mathrm{sta} - \mathrm{;CCCV} = \mathrm{stra} - \mathrm{;VC} = \mathrm{asz} - \mathrm{;VCC} = \mathrm{ing} - \mathrm{;VCCC} = \mathrm{inst} - \mathrm{;}.$
CVC = 'tal-'; CVCC = 'rend-'; CVCCC = 'monst-'; CCVC = 'kris-';
CCVCC = 'sport-'; CCVCCC = 'szkunksz-'; CCCVC = 'skrib-'; CCCVCC = 'strand-'.
Compare the notation of syllable fonts with examples:
$\mathrm{V} = {}^{\prime}\mathrm{a} - {}^{\prime};$
$\mathrm{C} = \mathrm{'s - '};$
CC = 'hm-';
[ \mathrm{CCC} = {}^{\prime}\mathrm{pszt} - {}^{\prime}; < \mathrm{pszt}; < \mathrm{p} < \mathrm{sz}; \mathrm{t} > ]
$\mathrm{CCCC} = \mathrm{'sscc - '}; < \mathrm{sscc} > ; < \mathrm{s} < \mathrm{sc} > \mathrm{c}>$
[ \mathrm{CV} = {}^{\prime}\mathrm{ka} - {}^{\prime}; < \mathrm{ka} >; < \mathrm{k} < \mathrm{a} > ]
CCV = 'sta-'; <sta>; <s < t <a>
$\mathrm{CCCV} = \mathrm{'stra - '}; < \mathrm{stra} > ; < \mathrm{s} < \mathrm{t} < \mathrm{r} < \mathrm{a}>$
$\mathrm{VC} = {}^{\prime}$ asz- $\cdot ^ { \text{一} }$ .<asz $>$ .<a>sz>
$\mathrm{VCC} = \mathrm{'ing - '}; < \mathrm{ing} > ; < \mathrm{i} > \mathrm{n} > \mathrm{g}>$
$\mathrm{VCCC} = \mathrm{'inst - '}; < \mathrm{inst > }; < \mathrm{i > n > s > t >}$
CVC = 'tal-'; <tal>; <t <a>1 >
CVCC = 'rend-'; <rend>; <r <e> n > d >
CVCCC = 'monst-'; <monst>; <m <o> n > s > t >
CCVC = 'kris-'; <kris>;<k<r<i>s>
CCVCC = 'sport-'; <sport>; <s <p <o> r > t >
CCVCCC = ' szkunksz-'; <szkunksz>; <sz < k <u> n > k > sz >
CCCVC = 'skrib-'; <skrib>; <s <k <r <i> b >
CCCVCC = 'strand-'; <strand>; <s <t <r <a> n > d >
This notation reflects the center-periphery model, in which vowels (V) are central and consonants (C) surround them in symmetrical layers. It supports linguistic modelling, phonological analysis, and database structuring for applications such as speech-to-text systems.
The database's code system is constructed by means of a symmetry-based classification method
a) The position within the syllable of consonants located on the periphery:
1. CVC-1 - the first consonant of the full syllable (occurs before the vowel)
2. CVC-2 - the second consonant of the full syllable (occurs after the vowel)
3. $CVCC-1$ – the first consonant of the full syllable (occurs before the vowel)
4. $CVCC-2$ – the second consonant of the full syllable (occurs after the vowel)
5. $CVCC-3$ – the third consonant of the full syllable (occurs after the vowel)
6. etc.
b) Encoded notation of syllable classes for vowels, e.g.:
CVCC:D, CVC:D, CV:D, V:D, VC:D, CVC:A1, CV:A1, V:A1, VC:A1, CVCC:C1, CVC:C1, CV:C1, V:C1, VC:C1, CVC:A2, CV:A2, V:A2, VC:A2, CVCC:B(1), CVC:B(1), CV:B(1), V:B(1), VC:B(1), CVC:C2, CV:C2, VC:C2, CV:A3, V:A3, CVC:B(2-1), CV:B(2-1), V:B(2-1), CVC:B(2-2), CV:B(2-2), VC:B(2-2), CVC:C3, CV:C3, etc.
This format—syllable structure: syllable type—offers a compact and highly systematic way to classify syllables both by internal composition and by their position within words.
# Examples:
$\gg$ CVCC: $D$ a full syllable in a one-syllable word form
» CVC:A1 – the word-initial full syllable in a two-syllable word form
» CVC:A2 – the word-initial full syllable in a three-syllable word form
$\gg$ CVC: $C1$ - the word-final full syllable in a two-syllable word form
$\gg$ CVC: $C3$ - the word-final full syllable in a four-syllable word form
$\gg$ CV: C1$ - the word-final open syllable in a two-syllable word form
$\gg$ VC:A2 - the word-initial closed syllable in a three-syllable word form
$\gg V: D$ - a reduced syllable in a one-syllable word form
$\gg$ CVCC: $B(1)$ - a word-internal full syllable in a three-syllable word form
$\gg$ CVC: $B(2-1)$ - the first word-internal full syllable in a four-syllable word form
$\gg$ CVC: $B(2-2)$ - the second word-internal full syllable in a four-syllable word form, etc.
This system enables precise and scalable classification of syllables based on both phonological structure and positional function within words.
c) Encoded notation of syllable classes for consonants, e.g.:
CVCC-1:D, CVCC-2:D, CVCC-3:D, CVC-1:D, CVC-2:D, CV-1:D, VC-1:A1, CVC-2:A1, CV-1:A1, VC-1:A1, CVCC-1:C1, CVCC-2:C1, CVCC-3:C1, CVC-1:C1, CVC-2:C1, CV-1:C1,
VC-1:C1, CVC-1:A2, CVC-2:A2, CV-1:A2, VC-1:A2, CVCC-1:B(1), CVCC-2:B(1), CVCC-3:B(1), CVC-1:B(1), CVC-2:B(1), CV-1:B(1), CVC-1:C2, CVC-2:C2, CV-1:C2, VC-1:C2,
CV-1:A3,CVC-1:B(2-1),CVC-2:B(2-1),CV-1:B(2-1),CVC-1:B(2-2),CVC-2:B(2-2),
CV-1:B(2-2),VC-1:B(2-2),CVC-1:C3,CVC-2:C3, CV-1:C3,etc.
This notation makes it possible to determine the exact position of a consonant within a syllable and its role in the larger word structure—capabilities that are indispensable for accurate phonological encoding, analysis, and synthesis in computational linguistics and speech technologies.
# III. RHYTHM-BASED PHONOLOGY
Following Róbert Gragger, it has been a widely held view in the scholarship for 100 years that—on content grounds—we do not know the Latin model of the poem titled Ómagyar Mária-siralom (hereafter OMS), while its rhythm is also surprising: “Für die Rhythmik ist unsere Marienklage eine Überraschung.” [4] From this, it follows that there is no demonstrable evidence that the author of OMS knew its source.
The difficulty arises from the conflation of an accentual and a quantitative incipit: "Es ist beachtenswert, wie tadellos das in trochäische Form gezwungene Gedicht mit ungarischer Takteinteilung klingt." [5] Thus, both the initial-stress accent and the long quantity fall on the first syllable of the metrical foot. PAN (Planctus ante nescia) employs a simultaneous system of versification, whereas OMS does not. I compared the versification of the complete Planctus ante nescia (hereafter PAN), prepared on the basis of the critical edition of the Carmina Burana, with the Hungarian versification of OMS. [6] The result was that, in place of Latin trochees, I found iambs in Hungarian, while elsewhere dactyls were rendered by dactyls. In the Hungarian verse form, only the quantitative system of versification emerged.
Highlighting the phonological examples below, I analyze typically doubtful word forms:
buntelen-byuntelen
$$
[\mathrm{C V C}: \mathrm{A}2]: [\mathrm{A}2 <\mathrm{B}(1) > \mathrm{C}2: \mathrm{B}1 ];
$$
$$
[\mathrm{C V}: \mathrm{B}(1)]: [\mathrm{A2} <\mathrm{B}(1) > \mathrm{C2}: \mathrm{B1} ];
$$
$$
[\mathrm{C V C}: \mathrm{C2}]: [\mathrm{A2} <\mathrm{B}(1) > \mathrm{C2}: \mathrm{B1} ]
# 3.1 „Bündten / Bündten
# 1. Context and Latin Equivalent
The disputed word form buntelen appears in the opening line of stanza 8/a of the poem:
Zsidó, mit tesz | törvénytelen, Fiam mert hal, | buntelen.
A Zsidó, amit tesz, az törvénytelen, mert a Fiam úgy hal meg, hogy buntelen volt (vö. 'buntelen Fiú - búnós világ' retorikai oposição). - What the Jew does is unlawful, for my Son dies although he was sinless (cf. the rhetorical opposition 'sinless Son - sinful world').
The Planctus source uses the expression sine culpa ('buntelenül' - 'without sin', 'innocently'). The Hungarian line presents Mary's argument: the Son dies because of the unlawful sins of the Jews, although he himself is sinless.
# 2. Orthographic and Philological Variants
The phonological value of the digraph $<\mathrm{yu}>$ and the stem-final vowel embedded in the privative suffix -talan/-telen explain how the paronomasia tör-veny-tlen $\sim$ bün-t-elen works alongside the trisyllabic $b(i)$ int(e)len: the privative suffix that arose from a compound (-ta/-ta) simultaneously preserves the Uralic stem-final vowel, which is indeed marked just as in the form szege- (cf. above, szeggel) but is no longer pronounced by speakers. In the Leuven Codex, $<\mathrm{yu}>$ represents a single, single-nucleus vowel of the "i + rounding" type (e.g., mezőül, vizeül, hevül; urumenttuul). According to A. Molnár, the hiatus-resolving reading (bi-ii) is nowhere motivated, and we have no independent root biü-. [7] In my view, however, in the word form under analysis the first part of the iamb is light and the second is heavy, closed by the coda -nt-; in the diphthong vs. monophthong dispute, the verse rhythm decides:
$$
<bi> + <\ddot{u}>n +t^{c}<le>n.
$$
<table><tr><td>Variant</td><td>Orthography</td><td>Phonological stem + suffix</td><td>Syllable count</td><td>Metrical alignment*</td></tr><tr><td>b(i)ünt(e)len</td><td>byunteLEN</td><td>biünte- + -len → [bi.ünt.len]</td><td>3 [CV.VCC.CVC]</td><td>✓ perfectly aligns</td></tr><tr><td>büntelen</td><td>byunteLEN</td><td>bún- + -telen → [bún.te.len]</td><td>3 [CVC.CV.CVC]</td><td>× iambic feet break</td></tr></table>
* The alignment was measured against the expected stress-/duration pattern on the 4th and 8th syllables.
# 3. Segmentation preferred by rhythm
The stanza parses into four-and-a-half iambic feet.
Two scenarios:
<table><tr><td>Variant</td><td>Mora Pattern</td><td>Mora Pattern</td><td>Mora Pattern</td><td>Mora Pattern</td><td>Feet Count</td></tr><tr><td>Fiam mert hal, biuntelen</td><td>U -</td><td>- -</td><td>U -</td><td>-</td><td>4</td></tr><tr><td>Fiam mert hal, buntelen</td><td>U -</td><td>- -</td><td>- U</td><td>-</td><td>4</td></tr></table>
<table><tr><td>metrical feet:</td><td>Fi-am</td><td>mert hal</td><td>bi-ünte-</td><td>len</td></tr><tr><td>mora pattern:</td><td>U -</td><td>- -</td><td>U -</td><td>-</td></tr></table>
4. Phonological and Morphological Implications
- Syllable Structure: Fiammert-hal, bi-ünte-len; CV-VC CVCC CVC CVVCC CVC (7 syllables; four-and-a-half iambic feet)
- Morpheme Boundary: biunt (ancient privative-derivational stem) + -len (privative suffix).
Sound Change: The metre preserves the word's phonological archaism (diphthong $\rightarrow$ long /'i/).
Prosody: The modern shortening (bün-telen) appears only when the poem is copied without
6. Summary for rhythm-based phonology
regard to metre. In this way, the poem's 154-foot / 133-word ratio is preserved.
5. Semantic nuance
The sound patterning and the adjacent alliteration with törvénytlen reinforces the rhetorical opposition "sinless Son — sinful world." The sense 'containing no sin' matches exactly the meaning of Latin sine culpa: 'bűntelenül' – 'innocently'.
<table><tr><td>Aspect</td><td>Rhythm-driven Decision</td><td>Phonological Description</td></tr><tr><td>Syllabification:</td><td>bi-ünte-len</td><td>3 syllables (1 easy + 1 heavy +1 heavy)</td></tr><tr><td>Syllable type:</td><td>CV-VCC + CVC</td><td>open + enclosed + full syllables type</td></tr><tr><td>Mora pattern:</td><td>u - | -</td><td>iambic group (u-)×3 + one half</td></tr><tr><td>Morpheme boundary:</td><td>biünte- + -len</td><td>ancient privative-derivational stem + privative suffix</td></tr><tr><td>Meaning:</td><td>‘bűnt nem tartalmazó’ – ‘sinless’ / ‘containing no sin’</td><td>sine culpa means: ‘bűntelenül’→ ‘innocently’, ‘without sin’</td></tr></table>
# 3.2 "hülj/hull"
# 1. Context and Latin Equivalent
The word form referring to water/blood cold appears in the closing question of stanza 3/b: szep-sé-göd | szé-gye-niül, | vé-red | húlj vizül?
A szépséged szégyenné alakul. Mint a viz, a vered hüljön meg? - Your beauty turns to shame. Shall your blood grow cold like water?
Latin parallel clause: Hinc ruit, hinc fluit unda cruoris ('im buzog, im omlik a vered arja' - 'lo, the torrent of your blood surges and flows').
# 2. Orthographic and Philological Variants
In the scholarly literature, the letters of the Leuven Codex have given rise to two competing readings: $\mathrm{h} < \mathrm{i}\mathrm{o} >$
a.) hulj imperative 'huljon' - 'may it grow cold'; progressive total assimilation of $/l/ + /j/ : [l:]\rightarrow$ <-ll>
b.) hull 'hullik', 'esik' - 'to fall', 'drop'; a mis-transcription of the assimilated <-ll> tradition.
Progressive $/l + \mathrm{j}/$ assimilation (cf. Balassi: felli, ell, etc.) is a common Old Hungarian phenomenon; therefore, the grapheme $< -\mathrm{ll}>$ does not denote a long $/1/$ , but the devoicing of the jussive $/ -\mathrm{j}/$ . [6], [8], [9], [10]
<table><tr><td>Variant</td><td>Orthography</td><td>Phonological stem + suffix</td><td>Syllable count</td><td>Metrical alignment*</td></tr><tr><td>húll</td><td>hioll</td><td>húl- + -j → [húlj]</td><td>1 [CVCC]</td><td>✓ perfectly aligns</td></tr><tr><td>hull</td><td>hioll</td><td>hull → [hull]</td><td>1 [CVCC]</td><td>✓ perfectly aligns</td></tr></table>
* The alignment was measured against the expected stress/duration pattern on the 3rd and 6th syllables.
# 3. Segmentation preferred by rhythm
The stanza is a four-foot dactylic; the 3rd foot is a spondee: $/ - /$ (édes ~ véré).
The second half of the question scans as follows:
hulj (CVCC; long [y:] + geminate [l:]) opens the 4th foot as a heavy syllable, vizül closes it with two light syllables, thus exactly filling the $/ - \mathrm{U} /$ pattern; the same pattern obtains with the word form hull, therefore, the rhythm of both variants is acceptable.
<table><tr><td>Variant</td><td>Mora Pattern</td><td>Mora Pattern</td><td>Feet Count</td></tr><tr><td>véred húlj vizül</td><td>- -</td><td>- U U</td><td>2</td></tr><tr><td>véred hull vizöl</td><td>- -</td><td>- U U</td><td>2</td></tr></table>
<table><tr><td>metrical feet:</td><td>vé-red</td><td>húlj vi-zül</td></tr><tr><td>mora pattern:</td><td>- -</td><td>- U U</td></tr></table>
# 4. Phonological and Morphological Implications
- Syllable structure: véred hülj vizül; CV-CVC CVCC CV-CVC (5 syllables; 1 spondee + 1 dactylic foot) - The final syllable -ül (in vizül) should not be analyzed as employing the long diphthong<eu>.
- Morpheme Boundary: hül- (verb stem) + -j (3rd-person singular imperative/jussive marker) → Hüljön (meg) a vēred! - May your blood grow cold! [11]
Sound Change: The direction of total assimilation is reversed relative to today's standard language: instead of being regressive, it is progressive: $\frac{1}{l} + \frac{j}{\rightarrow} [l]$, marked in writing as -ll, e.g., $h < \tilde{u} > l > 1$.
Prosody: The syllable sequence is heavy $+$ light $+$ light. The $\langle \mathrm{e}\ddot{\mathrm{u}}\rangle$ diphthong is not called for here, because it would make the metrical foot one syllable longer. The variant vizeül, proposed by Jakubovich-Pais for 'vizként' (as water), fails to meet the requirements of dactylic rhythm (vizül $\rightarrow$ vizeül). In stanza 3/b, the rhyme is a suffixal (grammatical) rhyme: mézül $\sim$ vizül. [6]
# 5. Semantic Nuance
Ruit and fluit in Latin denote rapid flow, not falling. The Son's life-giving blood comes to resemble water. According to late medieval medicine, the heat of outflowing blood is quickly lost. Mary's question—Véred hűljön meg, mint a víz? - Shall your blood grow cold, like water?—voices, in horror, this immediate cooling. By contrast, hull signifies mere gravitational falling and conveys neither the surge nor the loss of heat.
# 6. Summary for rhythm-based phonology
<table><tr><td>Aspect</td><td>Rhythm-driven decision</td><td>Phonological description</td></tr><tr><td>Syllabification:</td><td>húlj <húll></td><td>1 syllable (1 heavy)</td></tr><tr><td>Syllable type:</td><td>CVCC</td><td>full syllable type</td></tr><tr><td>Mora pattern:</td><td>- U U</td><td>The word form húlj provides the 4th dactyl.</td></tr><tr><td>Morpheme boundary:</td><td>húl- + -j</td><td>/1 + j/ → [l:] progressive total assimilation</td></tr><tr><td>Meaning:</td><td>‘húljön meg’, ‘veszítse el melegét’ – ‘may it grow cold’, ‘lose its heat’</td><td>The semantic shift—namely, the cooling of the flowing blood—accords with the ruit/fluit dynamism.</td></tr></table>
# IV. LINGUISTIC MELODY
# 4.1 The Iambic Meter of the Fragment of the Hun Trilógia (The Hun Trilogy)—János Arany's Late Epic Diction
Lajos Áprily's 7- and 6-syllable iambic line was not unknown in earlier Hungarian poetry; cf. the twentieth-century Hungarian poet Lajos Áprily's poem titled Ómagyar María-siralom from 1938. [12]
Hul-lo | kony-nyem | mu-tat-|ja | szün-te-|len so-|ha-jom, a
- - | - - - | U - | U | - U | - - | U -
hogy meg-|gyö-tör |se-bé-|vel | a bel-|só faj-|da-lom.
He had already used it in the epic The Hun Trilogy, where he versified his hero Attila in alexandrines composed of two four-and-a-half-foot iambic lines. One might suppose that Arany took his model from the Nibelungenlied, since he translated four stanzas from the Nibelungenlied the Twenty-Fifth Adventure which is related to PAN stanzas 6a-6b, dividing the closed lines with diaereses [13]:
# The Twenty-Fifth Adventure
Ott allt szegeny papocska, razvan lucskos mezét.
Megtudta Hagen ebből, hogy nem hazug beszed a
Aizonyos halal, mit jósolt a hableany;
Gondolta: mind ehósok ott vesznek, igazán.
# PAN 6a-6b in Hungarian
Ógaz Simeonnak | bez-zeg | sza-va | é-re, a
u - | - - | u - | - - | - - | u u | - -
Enérzemezbútó rot, kitnéz hái gé-re. a
U - | U - | - - | - | - | U - | - -
Si-ral-mam, fo-há-sza-tom | te-rít-he-tók | kívül,
U - | - U | - U | - | U - | U - | -
Enjon-hom-nak elu-ja,$\parallel$ kisom ha nem hé-vül.
In the Nibelungenlied quotation, we see that the iambic anacusis is absent at the beginning of the line or after the main caesura—something that is very much present in ÓMS and is characteristic of János Arany's ingenious late epic poetry:
# From the first part of the Csaba trilogy
A mult | i-dok | ho-má-|lyán | meg-szó-|lal egy | re-ge
U - | U - | U - | - | - - | U - | U -
<table><tr><td colspan="2">Mint el-|ha-lo | menny-dör-|gés, fü-lem-|ben é-|ne-ke;</td><td>a</td></tr><tr><td colspan="2">- - |U - | - - - | - | U - | U - | U -</td><td></td></tr><tr><td colspan="2">Mint nagy | vi-zek | mo-raj-|ját, mely-tól | zúg a | va-don,</td><td>b</td></tr><tr><td colspan="2">- - |U - | U - | - | - - | - U | U -</td><td></td></tr><tr><td colspan="2">Vér-rel | fo-lyó | na-pok | bús pa-nasz-|száth hall-|ga-tom.</td><td>b</td></tr><tr><td colspan="2">- - |U - | U - | - | U - | - - | U -</td><td></td></tr></table>
The iambic anacruses in János Arany's The Hun Trilogy can be observed in The Csaba Trilogy, Part I [First Canto: Átila and Buda; Second Canto: Átila Goes A-Hunting], as well as in The Csaba Trilogy, Part III [First Canto: Átila Dies (Fragment from the First Canto); Second Canto: The Bride's Awakening; Third Canto: Zoárd's Counsel; Fourth Canto: Átila on the Pall].
From the above list, it may be concluded that an iambic anacusis—at the beginning of the line or in the metrical foot following the main caesura—is by no means alien to János Arany; cf. Zoltán Kodály's opposing view of the iambic verse forms of Arany and Petőfi: “with a heavy beginning, completely omitting the iambic cadence.” [14]
From the dictionary section of The Reverse Dictionary of Hungarian Word Endings [15], I syllabified the headwords: 58,301 dictionary entries. In these, I counted the possible metrical feet and found a total of 164,234. I have summarized the relative proportions of the metrical feet in the table below:
<table><tr><td colspan="3">Metrical Feet</td></tr><tr><td>Total (count):</td><td>164.234</td><td>100%</td></tr><tr><td>Pyrrhic</td><td>30.792</td><td>18,75%</td></tr><tr><td>Spondee</td><td>39.877</td><td>24,28%</td></tr><tr><td>Iamb</td><td>32.543</td><td>19,82%</td></tr><tr><td>Trochee</td><td>42.750</td><td>26,03%</td></tr><tr><td>Anapest</td><td>7.701</td><td>4,69%</td></tr><tr><td>Dactyl</td><td>10.571</td><td>6,44%</td></tr></table>
From the table, it is evident that trochees have an advantage over iambs; nevertheless, the number of iambic feet is still high—nearly $20\%$ of the 164,234 metrical feet examined. [16] If János Arany had known the text of PAN, he would have been able to translate it in iambs, as the author of OMS did. Indeed, I am of the view that Arany may have known the PAN text in fragmentary form-from two seventeenth-century hymnals, the Kájoni Kancióná and the Cantus Catholici. The complete version of PAN might also have reached him, via the Library of the Hungarian Academy of Sciences, from Schauspiele des Mittelalters. [17] János Arany was not only a poet; he also composed melodies for his own poems and for those of others. His original melodies were published by Zoltán Kodály on the basis of István Bartalus's work. [14] Bartalus's manuscript, in 1875, mentions the first piece to be notated—one that is important for us from the perspective of OMS. [18] Zoltán Kodály considers this five-line melody unusual in its form. [14]
This is confirmed by András L. Kecskés, an expert in early music: "The textless piece's unusual major-minor melody stands out among Arany's compositions, not to mention the possible $4 \times 7$ verse form" [19]; cf. the $5 \times 7$ verse form.
According to Kodály, the melody's text is a well-known snippet of a humorous folk rhyme, e.g.:
Zsidó, zsidó, vak apád!
Még nem szól szalonnát?
Láda magyar mögöszi,
Drága pénz mögöszi;
De a zsidó nem öszi,
Mér a fene mögöszi! [20]
All the same, if the text of PAN surfaced in the Kájoni Kancióné and the Cantus Catholici, then for János Arany's song composition the Hungarian text of ÓMS 8b could likewise have been recalled in the Latinate $5 \times 7$ stanza even in the nineteenth century: Kegyedjetek fiamnak, ne légy kegyelm magamnak! – “Show favour to my son be not gracious to me!”
cf. the two iambic rhythms, namely in phrases built on the shared root "kegy-":
1. The one in Bolond Istók: “kegyelmes herceg” (gracious prince)
2. And the one in OMS.: "kegyedjetek fiamnak" (show favour to my son). [13]
The first line of the original PAN 8a-8b sequence is a reprise (recurring) melody; therefore, the stanza is not five lines but, musically, four-something János Arany did not take into account.
Instead of pairing János Arany's melody with a humorous folk rhyme, I assigned to it the text from ÓMS—the catchy God-lament of the Virgin Mary—from stanza 8b, as in the score edition [14]; cf. Bartalus's manuscript II. [18]:

Szilard Ferenc Kovacs, a church musician, adapted Arany's scholarly version to the verse rhythm, then—using the pitches Arany employed—brought the melody closer to the
desired character (secular versus ecclesiastical). The score is published with the oral approval of Szilard Ferenc Kovacs.
1. Using the pitches employed by János Arany, with only the order modified.
Az Arany által használt hangok felhasználásával, csupán a sorrendén módosítva

Ke-gyögy-gye-tok fi-am-nak, nelegy ke-gyolm ma-gam-nak, a-vagy ha-lal
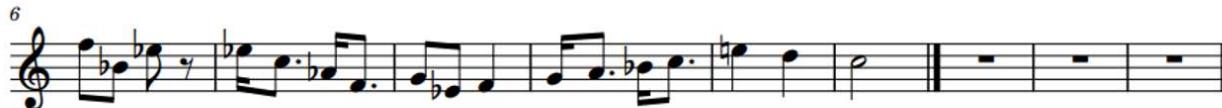
ki-ná-al, a-nyat é-zes fi-á-al e-gyem-be-lü ol-jé-tok!
2. The Arany version adjusted to the verse rhythm.

Ke-gyögy-gye-tok fi-am-nak, nelegy ke-gyolm ma-gam-nak, a-vagy ha-lal ki-na-al,

a-nyaté-zes fi-á-al e-gyem-be-lu ol-jé-tok!
In the PAN 8a-8b sequence, the Latin trochaic cadence and the reprise melodic section are clearly traceable; score edition [21]:

VIII. 63. Quod cri-men, que sce-le-ra
Gens com-mi-sit ef-fe-ra! Vin-cla, vir-gas, vul ne-ra,
68. Na-to, que-so, par-ci-te, Ma-trem cru-ci-fi-gi-te Aut in crucis stipite
1st line of verse:
63. -U | -U | -U | -
X X X X X X X
64. -U|-U|-U|--U|-U|-U|-
$\dot{\mathbf{x}}$ X | $\dot{\mathbf{x}}$ X | $\dot{\mathbf{x}}$ X X
2nd line of verse:
68. U U U U
X X X X X X X
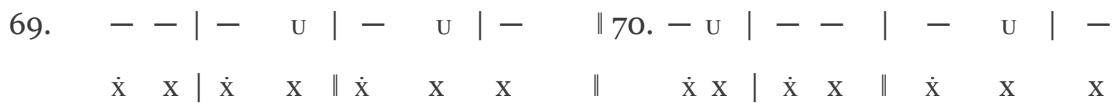

# 1st line of verse:
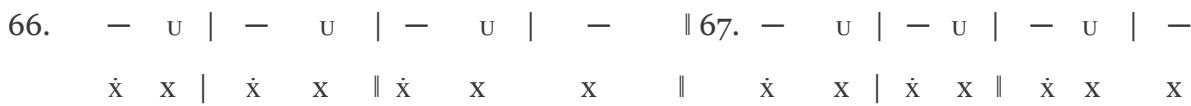
2nd line of verse:
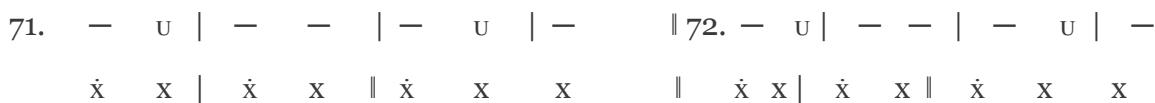
János Arany's composition—preserved without text but connectable to the iambic rhythm of OMS—supports the hypothesis that Bence Szabolcsi rhythmized the principal line of OMS incorrectly from a musical standpoint ("Kegyöggyetök fiamnak, Ne légy kegyölöm magamnak" – "Show favour to my son be not gracious to me!"), since it is not sufficient to consider PAN alone, score edition [22]:



# 4.2 Representing Meter
I represent a meter in an abstract manner. It is well known that in quantitative versification the duration value of a short syllable (mora) is one unit $(\mathrm{U} = 1)$, while the duration of a long syllable is two units $(1 + 1)$ . a) In the left-hand plots below, the horizontal axis shows the number of syllables, and the vertical axis shows the pronunciation time of each syllable. Vertical lines serve to delimit the quantitative metrical feet. Thus, the foundations of metrics do not in themselves address the relationship between the verse line and the melody. [23]
b) In the right-hand plots below, the horizontal axis shows quantitative syllabification (long–short, short–long), while the vertical axis shows pitch (melody), labelled by note name. In this way, the theory substantiates the relationship between language and melody.
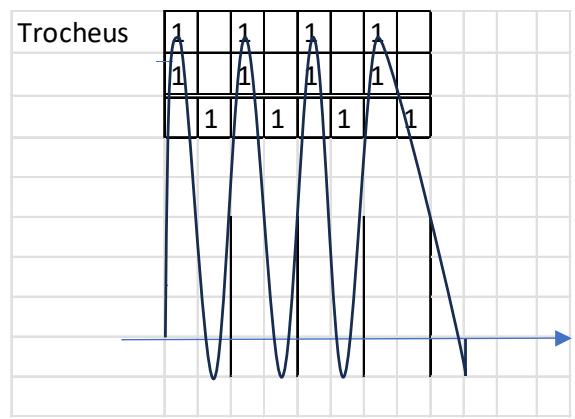
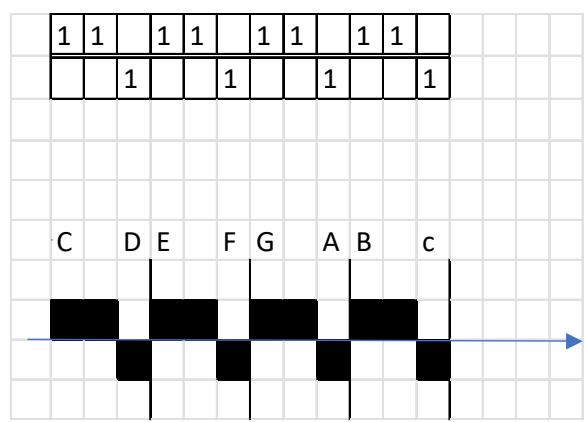
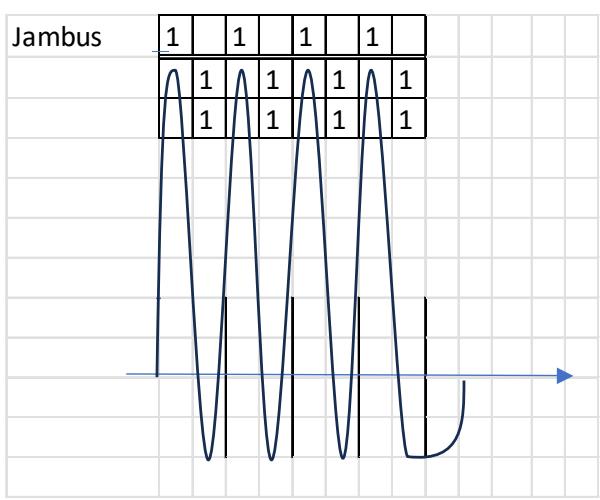
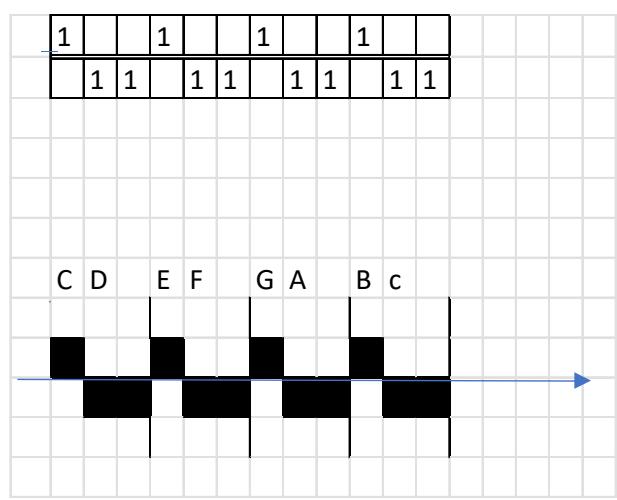
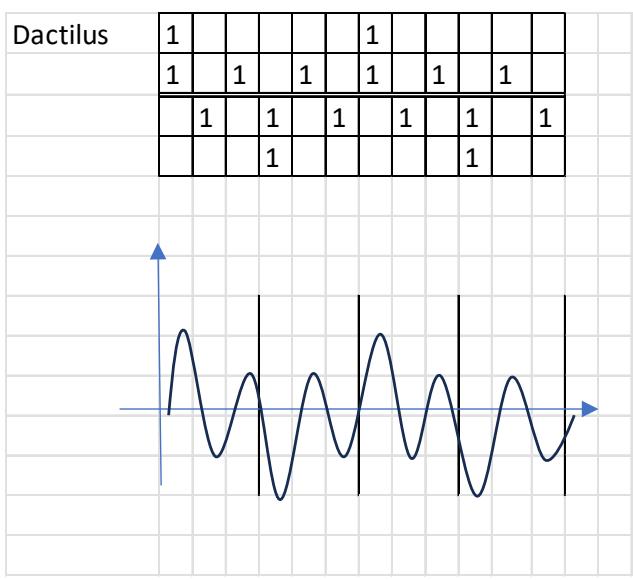
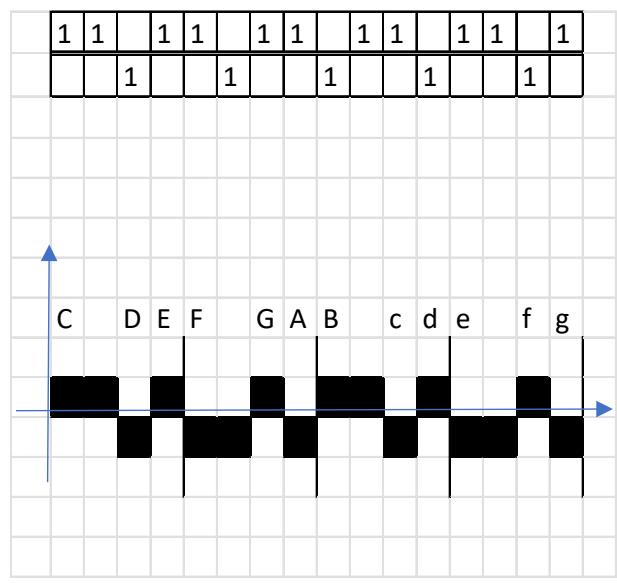
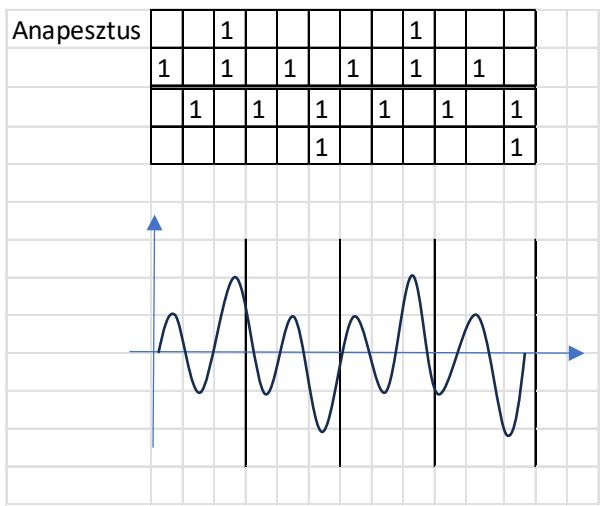
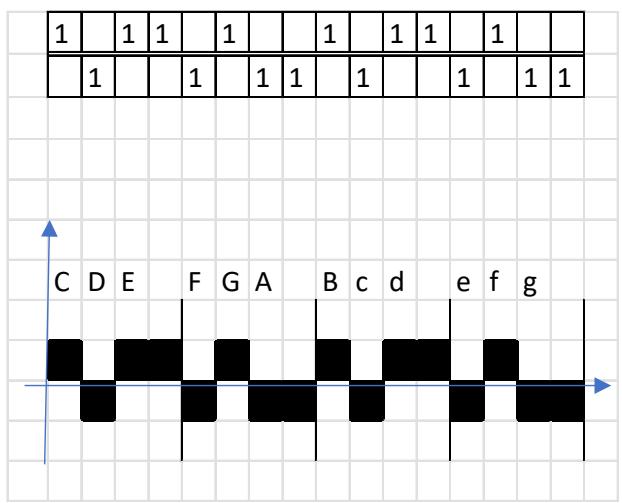
A characteristic property of a pitch series is that, under certain conditions, rhythm emerges—on the basis of temporal relations and stress hierarchies. The example below illustrates, in the PAN 2a-2b sequence, the four-and-a-half-foot trochaic meter and the three-beat heptasyllabic rhythm, as well as the melody with long and short syllables; score edition. [24]

1st line of verse:
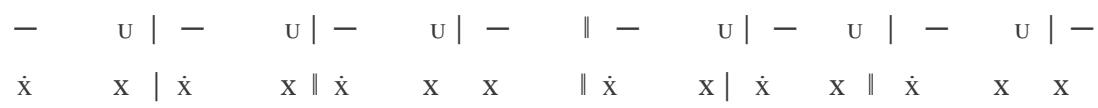
2nd line of verse:
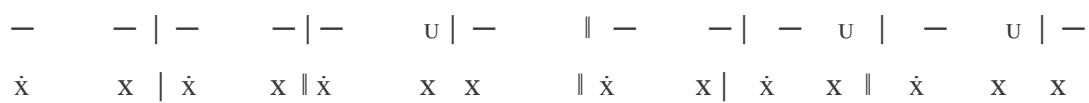

1st line of verse:
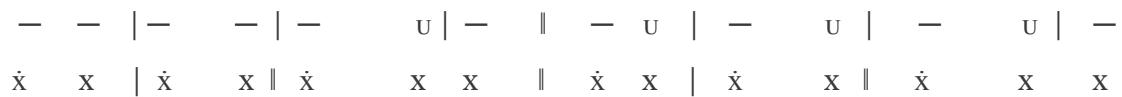
2nd line of verse:
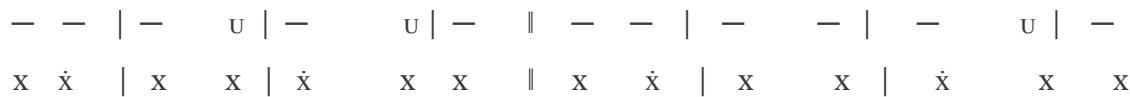
In the 7a-7b sequence, Jammers enforces the rhythm of the Adonic lines, with melodies:

1st line of verse:
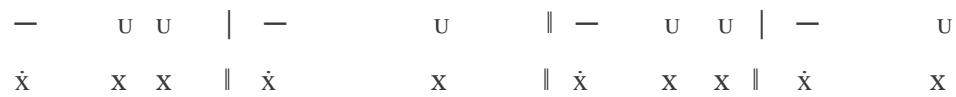
2nd line of verse:
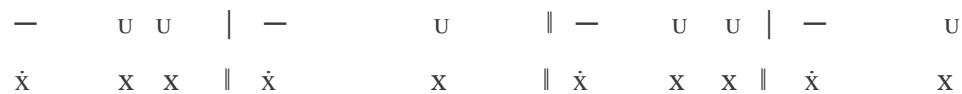

1st line of verse:

2nd line of verse:

Using the melodies of PAN 1a-1b and 6a-6b, as well as 3a-3b, I demonstrate the opposition between the prevailing trochaic and dactylic lines—an opposition that OMS also preserved, score edition. [21]
PAN 1a-1b:


3. Crucior dolore,
6. Gaudio, dulcore.
Lines 1-2 of the verse:
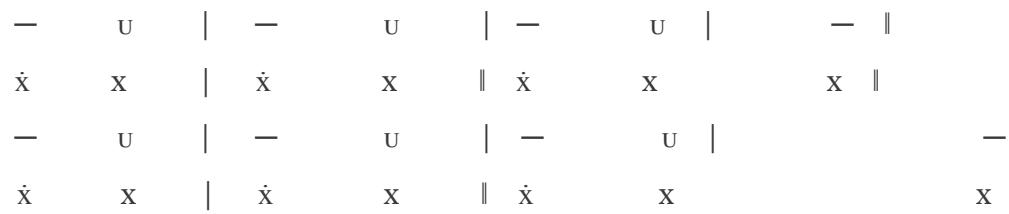
3rd line of the verse:
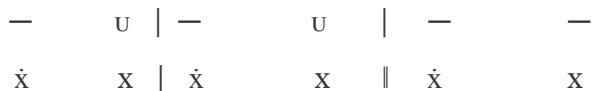
Lines 4-5 of the verse:
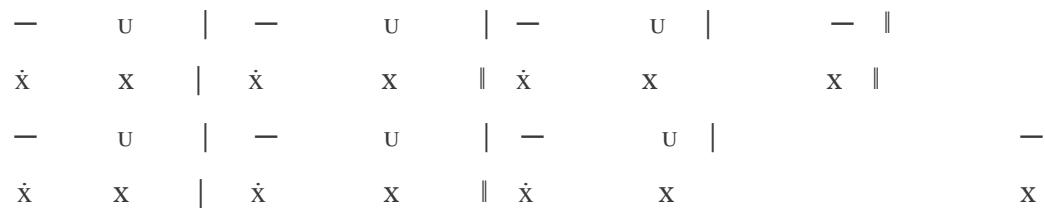
6th line of the verse:
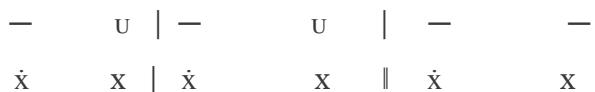
PAN 6a-6b:


Lines 47-48 of the verse:
<table><tr><td>-</td><td>U | -</td><td>U | - U | -</td><td>| -</td><td>U | - U | -</td><td>| -</td><td>-</td><td>| -</td><td>U | - U | -</td><td>-</td><td>- |</td></tr><tr><td>x</td><td>X | x</td><td>X | x</td><td>x</td><td>x</td><td>x</td><td>x</td><td>| x</td><td>X | x</td><td>x</td><td>x</td></tr></table>
Lines 49-50 of the verse:
<table><tr><td>-</td><td>U</td><td>|</td><td>-</td><td>-</td><td>|</td><td>-</td><td>U</td><td>|</td><td>-</td><td>|</td><td>-</td><td>U</td><td>|</td><td>-</td><td>U</td><td>|</td><td>-</td><td>-</td><td>|</td></tr><tr><td>\(\dot{\mathbf{x}}\)</td><td>X</td><td>|</td><td>\(\dot{\mathbf{x}}\)</td><td>X</td><td>|</td><td>\(\dot{\mathbf{x}}\)</td><td>X</td><td>|</td><td>\(\dot{\mathbf{x}}\)</td><td>|</td><td>\(\dot{\mathbf{x}}\)</td><td>X</td><td>|</td><td>\(\dot{\mathbf{x}}\)</td><td>X</td><td>|</td><td>\(\dot{\mathbf{x}}\)</td><td>X</td><td>|</td></tr></table>
Lines 51-52 of the verse:
<table><tr><td>-</td><td>U | -</td><td>-</td><td>- | -</td><td>U | -</td><td>-</td><td>-</td><td>U | -</td><td>U | -</td><td>- | -</td></tr><tr><td>x</td><td>x | x</td><td>x | x</td><td>x</td><td>x</td><td>x</td><td>x</td><td>x</td><td>x | x</td><td>x | x</td></tr></table>
Lines 53-54 of the verse:
<table><tr><td>-</td><td>U</td><td>|</td><td>-</td><td>-</td><td>|</td><td>-</td><td>U</td><td>|</td><td>-</td><td>|</td><td>-</td><td>-</td><td>|</td><td>-</td><td>U</td><td>|</td><td>-</td><td>-</td></tr><tr><td>\(\dot{\mathbf{x}}\)</td><td>X</td><td>|</td><td>\(\dot{\mathbf{x}}\)</td><td>X</td><td>|</td><td>\(\dot{\mathbf{x}}\)</td><td>X</td><td>|</td><td>\(\dot{\mathbf{x}}\)</td><td>X</td><td>|</td><td>\(\dot{\mathbf{x}}\)</td><td>X</td><td>|</td><td>\(\dot{\mathbf{x}}\)</td><td>X</td><td>|</td><td>\(\dot{\mathbf{x}}\)</td></tr></table>
PAN 3a-3b:

Lines 15-20 of the verse:
<table><tr><td>-</td><td>U U</td><td>| -</td><td>U</td><td>U | -</td><td>U U | -</td><td>U</td><td>U</td><td>| -</td><td>U</td><td>U</td><td>| -</td><td>U</td><td>-</td><td>U</td></tr><tr><td>-</td><td>U U</td><td>| -</td><td>U</td><td>U | -</td><td>U U |</td><td>-</td><td>U</td><td>U</td><td>|</td><td>-</td><td>-</td><td>-</td><td>-</td><td>U</td></tr><tr><td>X</td><td>X X</td><td>| X</td><td>X</td><td>X | X</td><td>X | X</td><td>X</td><td>X | X</td><td>X</td><td>X | X</td><td>X</td><td>X</td><td>X</td><td>-</td><td>X</td></tr><tr><td>X</td><td>X X</td><td>| X</td><td>X</td><td>X | X</td><td>X | X</td><td>X</td><td>X | X</td><td>X</td><td>X | X</td><td>X</td><td>X</td><td>X</td><td>-</td><td>X</td></tr></table>
Lines 21-26 of the verse:
<table><tr><td>-</td><td>U U</td><td>| -</td><td>U</td><td>U | -</td><td>U U | -</td><td>U</td><td>U</td><td>| -</td><td>U</td><td>U</td><td>| -</td><td>U</td><td>-</td><td>U</td></tr><tr><td>-</td><td>U U</td><td>| -</td><td>U</td><td>U | -</td><td>U U |</td><td>-</td><td>U</td><td>U</td><td>|</td><td>-</td><td>-</td><td>-</td><td>-</td><td>U</td></tr><tr><td>X</td><td>X X</td><td>| X</td><td>X</td><td>X | -</td><td>X -</td><td>X -</td><td>X -</td><td>X | -</td><td>X -</td><td>X -</td><td>X -</td><td>-</td><td>-</td><td>-</td></tr><tr><td>X</td><td>X X</td><td>| X</td><td>X</td><td>X | -</td><td>X -</td><td>X -</td><td>X -</td><td>X | -</td><td>X -</td><td>X -</td><td>X -</td><td>-</td><td>-</td><td>X</td></tr></table>
Under the influence of Bence Szabolcsi, to this day, when OMS is performed in song, a trochee is incorrectly imposed on an iambic foot; score edition [22]:
Plan-cactus an-te ne-sci-a
Or-bat or-bem ra-di-o
Va - lék si - ralm - tu - dat - lan,
Vá - laszt vi - lá - gom - tól

Fi-li, dul-cor u-ni-ce, Sin-gu-la-re gau-di-um, Pe-c tus, men-tem, lu-mi-na Tor-quent tu-a vul-ne-ra;
é-zes u-ra-dom, E-gyen-egy fi-a-dom, Sze-mem kony-vel á-rad, En-hom bu-val fá-rad, Vi-lág vi-lá-ga, Vi-rág-nak vi-rá-ga,

\[
\begin{array}{c c c c c c c c c c} \text{Ma - trem flen - tem} & \text{re} & \text{-} & \text{spi - ce}, & & \text{Con - fe - rens} & \text{so - la} & \text{-} & \text{ti - um}. \\ \text{Quae ma - ter, quae} & \text{fe} & \text{-} & \text{mi - na} & & \text{Tam} & \text{fe - lix,\_} & \text{tam} & \text{mi} & \text{-} & \text{se - ra?} \end{array}
\]
Sí -ró a -nyat te-kint-sed Bu-ja be-lul ki-nyuh-had. Te -ve -rod hul -lot-ja En -jon-hom o-le-lot-ja.
Ke-se-rui-en kin-za-tol, Vas-sze-gek-kel ve-re-trol.
In the short lines, with respect to the two-layer versification of PAN and OMS, Bence Szabolcsi fails to recognize the dactyl; score edition [22]:

Flos flo - rum, Dux mo - rum, Ve - ni - ae ve - na,
Proh do - lor, Hinc co - lor Ef - fu - git o - ris,
O ne -kem En fi - am E - zes me -zul,
Vegy ha - lal En - go - met, E - gye-dom el - jen,

Quam gra-vis In cla-vis Est ti-bi poe-na!
Hinc ru-it, Hinc flu-it Un-da cru-o-ris!
Sze-gye-nul Szep-sé-ged, Vé-röd hull vül.
Ma-rad-jon U-ra-dom, Kit vi-lag fel-jen.
cf. [21]:

15. Flos flo - rum, Dux mo - rum, Ve - ni - e ve - na, 18. Quam gra - vis In cla - vis Est ti - bi pe - na!
m. 21. Proh do - lor, Hinc co - lor Ef - fu -git o - ris, 24. Hinc ru-it, Hinc flu-it Un - da cru - o - ris!
The flagship of ÓMS is music. In the company of sacred folk hymns, the largest-scale musical work known today about ÓMS was composed by Ferenc Ottó, a student of Zoltán Kodály. His 80-minute oratorio The Hungarian Passion (formerly Mary's Lament) is forthcoming—cf. [25]
# V. SUMMARY
# A. Thesis and Interpretive Framework
The study's opening sentence—"The relationship between consciousness and linguistic data to formalize, using symmetry principles I have identified to formalize that relationship"—is interpreted to mean that consciousness as a biological fact and formalized linguistic data are mirror images of one another: the organizing principles of conscious processing appear in linguistic structures as systems of symmetry, and conversely, the symmetries demonstrable in language reflect the organization of consciousness. The study makes this mirror-like correspondence accessible and measurable through a symmetry-based formalization. The symmetry-theoretical framework rests on three coequal pillars: (1) machine encoding (based on syllable and word position, using a center-periphery model), (2) rhythm-based phonology (patterns of quantitative meter and stress in historical texts), and (3) linguistic melody (the alignment of intonation and meter). The integration of these three perspectives provides the internal logic for formalizing the "consciousness-language" relationship.
# B. Theoretical Novelty and Model
Symmetry as a central concept is not merely a descriptive metaphor: explicit encoding schemes and positional labels carry the structure through at the database and algorithmic levels. The core center-periphery model represents the vowel (V) as the center and the consonants (C) as concentric, symmetrical layers $(\mathrm{C} < \mathrm{C} < \mathrm{C} < \mathrm{V} > \mathrm{C} > \mathrm{C})$ which brings both the syllable types and the within-syllable positions of phonemes into a unified notation.
The study also introduces a formal, "search-styled" relational notation:
CONSCIOUSNESS (search) = [1:2]: [3:4], where (1) is the syllable template, (2) the syllable's word-initial/medial/final status, (3) the relative position within the word, and (4) the word category by syllable count. This compact notation expresses the mutual mapability of linguistic rhythm and structural placement—a mirror correspondence between the "biological" organization of consciousness and the "formal" linguistic data.
# c. Methodology: Three Coequal Pillars
d. Machine encoding symmetry-based classification The classification of linguistic units into word types by syllable count (D, A, B1...B8) and the resulting set of 55 derived syllable types is designed to make rhythmic and positional information algorithmically manageable. Syllables fall into five main structural classes (reduced, inorganic, open, closed, full), with a detailed repertoire of CV patterns, all unified by the center-periphery model. The positional encoding of phonemes (e.g., CVC-1, CVC-2; CVCC-1/2/3, etc.) and the systematic labelling of syllable types (CVCC:D; CVC:A1; ...) capture both internal composition and function within the word; this dual code produces a queryable, scalable database for speech-to-text systems and computational linguistics.
1. Rhythm-based phonology-historical case studies
The versification of the Ómagyar María-siralom (ÓMS) is compared on the basis of the critical edition of the Latin Planctus ante nescia (PAN): while the dominance of Latin trochaic formations is well known, the Hungarian text exhibits iambic solutions, and dactyl-dactyl correspondences can also be demonstrated. Two detailed philological-phonological case studies show how meter decides between graphic variants: (1) in the case of biüntlen/buntelen, iambic fit supports the segmentation $bi$ - $inte$ -len; (2) in the case of hülj/hull, both progressive $/l + j/$ assimilation and the dactylic pattern are consistent with the reconstruction hülj, while "hull" does not violate the rhythm either but carries a different semantic drift. These examples demonstrate the role of rhythm as arbiter amid orthographic uncertainties and show the practical disambiguating power of formal metrical description.
1. Linguistic melody - aligning meter and intonation
The study also provides an abstract, functional representation of meter (duration-syllable functions, pitch-time mappings), and through historical examples—including János Arany's late epic diction and melodic materials—demonstrates how pitch contours align with metrical feet and caesuras. In certain PAN sequences, the separately discussed trochaic and dactylic lines, as well as the melodic linkages of Adonic formulas, shed light on a two-level organization (metrical and melodic); this duality further justifies a reconfiguration of OMS performance practice (e.g., a critique of traditional trochaic "overlays" imposed on iambic principal lines).
# IV. RESULTS AND CONTRIBUTIONS
- Unified Encoding Architecture: The study develops a compact, formal notation system that can handle, within a single framework, the internal structure of syllables, positions within the word, and rhythmic aspects. This notation directly "maps" the structures of conscious linguistic composition onto the raw data—and, conversely, makes it possible to read back the organizing principles of consciousness from the formalized data structures (a mirror-like correspondence).
- Rhythmic disambiguation and reconstruction: Meter-driven analysis makes it possible to resolve doubtful forms (e.g., biuntlen / buntelen; hulj / hull); in phonological-morphological boundary cases, rhythm signals the preferred reading. This procedure is directly applicable in philological reconstructions and critical editions.
Modelling the Rhythm-Melody Interface: The formal linkage of duration and pitch makes prosodic patterns quantifiable. Examples demonstrating the interaction between linguistic melody and meter (e.g., PAN 1a-1b, 6a-6b, 3a-3b; Adonic formulas) also cast the performance rhythm of OMS in a new light.
- Empirical Background and Typological Balance: The metrical-foot distribution report (a foot count in the tens of thousands over dictionary data) statistically confirms that the iamb is not a marginal phenomenon ( $\approx 20\%$ ) within the Hungarian rhythmic inventory, even though the trochee's advantage is demonstrable; this aligns with the picture of rhythmic diversity found in Hungarian historical material.
# VI. PRACTICAL APPLICABILITY
The formalized, symmetry-based encoding offers added value across multiple application areas: (1) speech recognition—by incorporating rhythmic and positional features, more robust acoustic-language models can be built; (2) speech synthesis—explicit handling of the melody-duration interface yields more natural prosody; (3) NLP tasks—automatic detection of morpheme boundaries and syllabification, rhythm-sensitive text generation; (4) philology and performance practice—reconstruction of rhythm and melody in historical texts, and correction of misleading traditions (e.g., trochaic overlays). The study emphasizes that seeing the three pillars together is indispensable for designing the linguistic layer of high-speed, scalable “terminal-to-terminal” communication as well (speech-to-text systems, database structures).
# VII. CONCLUSION
The results presented argue that the consciousness-language relationship can be formalized along symmetry principles: the rhythmic-structural organization of consciousness and the formal patterns of linguistic data mutually reflect one another. Machine encoding (positional and structural labelling), rhythm-based phonological decision-making, and the model of linguistic melody together offer an integrated, bidirectional framework in which the architecture of conscious language use and the isomorphic (mirror-image) correspondence of formalized linguistic data can be demonstrated and reutilized—both for theoretical understanding and for technological implementations.
The author declares no conflicts of interest.
The analysis above was created with the assistance of ChatGPT.
Generating HTML Viewer...
− Conflict of Interest
The authors declare no conflict of interest.
− Ethical Approval
Not applicable
− Data Availability
The datasets used in this study are openly available at [repository link] and the source code is available on GitHub at [GitHub link].






